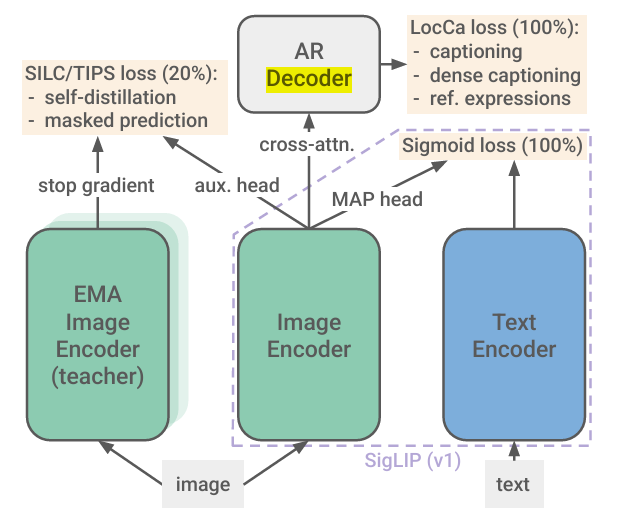
- decoder-based pretraining (위치 파악 능력 강화)
기존 CLIP 스타일 모델은 ‘이미지에 고양이가 있다’처럼 대상을 인식하는 데는 강점이 있었지만, ‘왼쪽 소파 위에 잠자는 고양이’ 처럼 구체적인 위치를 정확히 파악하는 데는 한계가 있었습니다.
SigLIP 2는 이미지 인코더에 텍스트를 생성하는 트랜스포머 디코더를 결합해, ‘이미지 캡션 생성’이나 ‘특정 영역 설명 예측’ 같은 과제를 함께 학습합니다. 이런 과정을 거치며 모델은 이미지 속 객체들의 공간적 관계와 위치를 더욱 세밀하게 이해합니다.
- Training with self-distillation and masked prediction (세부 묘사 능력 극대화)
SigLIP 2는 ‘교사-학생(teacher-student) 구조’의 ‘자기 증류(self-distillation)’와 ‘마스크 예측 기법(masked prediction)’을 활용합니다.
여기서 학생 모델은 이미지의 일부만 보거나 일부가 가려진 상태로 입력을 받는 반면, 교사 모델은 전체 이미지를 바탕으로 특징을 추출합다. 이렇게 두 모델을 비교하며 학생 모델이 교사 모델의 표현 방식을 자연스럽게 따라가도록 훈련합니다.
이 방식 덕분에 모델은 이미지의 전체 맥락은 물론, 픽셀 단위의 미세한 질감이나 형태와 깊이 같은 고밀도 정보를 익히게 됩니다. 결과적으로 이미지 분할이나 3D 복원처럼 정교한 작업의 토대를 마련할 수 있습니다.
- Architecture, training data, optimizer
모델의 성능은 결국 데이터에 의해 결정됩니다.
SigLIP 2는 전 세계 109개 언어를 아우르는 100억 장의 이미지와 120억 개의 텍스트로 구성된 대규모 WebLI 데이터셋을 기반으로 학습되었습니다. 특히, 영어 데이터(90%)와 비영어 데이터(10%)를 혼합하여 특정 언어에 치우치지 않고 균형 잡힌 다국어 성능을 발휘합니다.
주요 벤치마크 결과
SigLIP 2의 우수성은 구체적인 수치로 드러났습니다.
SigLIP 2는 제로샷 분류(zero-shot classification)와 이미지-텍스트 검색의 주요 평가 지표에서 이전 세대인 SigLIP 모델뿐만 아니라 다른 공개 모델들 보다, 모든 규모 대비 우수한 성능을 보였습니다.
이로써 새로운 학습 레시피(training recip)가 전반적인 시각적 이해 능력을 크게 향상시켰음을 알 수 있습니다.
SigLIP 2는 다국어 성능 평가 데이터셋 XM3600에서 이전 SigLIP보다 훨씬 더 높은 검색 정확도(recall)를 보여줬습니다. 또한 다국어 데이터로만 학습한 mSigLIP 모델의 성능에 거의 근접하면서도, 영어 기반 벤치마크에선 오히려 더 뛰어난 결과를 기록했습니다.
이로써 ‘다국어 지원’과 ‘영어권 성능’이라는 두 가지 목표를 모두 충족시켰습니다.
- SigLIP 2 as a vision encoder for VLMs
SigLIP 2는 단독으로도 뛰어난 성능을 보이지만, 대규모 언어 모델(LLM)과 결합될 때 그 진가를 발휘합니다.
실제로 Gemma 2 LLM에 SigLIP 2를 시각 인코더로 적용했을 때, 기존 SigLIP이나 AIMv2 인코더를 사용했을 보다 VLM(Vision-Language Model)의 전반적인 성능이 뚜렷하게 향상되었습니다.
성능을 넘어: 더 책임감 있고 다재다능한 AI로
SigLIP 2는 단순히 성능을 높이는 데 그치지 않고, AI가 사회에서 어떤 책임을 지고 어떻게 활용될 수 있을지에 대한 깊은 고민도 함께 담아냈습니다.
AI 모델의 편향 문제는 사회적으로 무척 중요한 이슈입니다. SigLIP 2는 편향 제거 기술을 훈련 데이터에 적용하면서 이 문제를 적극적으로 해결하고자 했습니다.
실제로 모델이 임의의 객체를 특정 성별과 연결하는 '표현 편향' 수치는 기존 L/16 모델에서 35.5% → 7.3%까지 크게 낮아졌습니다.
이런 변화는 AI가 더욱 공정하고 신뢰할 수 있는 방향으로 나아가는 데 의미 있는 진전이라고 볼 수 있습니다.
문화적 다양성을 평가하기 위해 DollarStreet, GeoDE, GLDv2 같은 데이터셋을 활용해 제로샷 분류 정확도를 측정했습니다. 또한, DollarStreet와 GeoDE에서는 10샷 지리적 위치 파악(10-shot geolocalization) 실험도 진행했습니다.
총 2만 1천 장의 이미지를 분석한 결과, 동일한 모델 크기와 해상도에서 SigLIP 2가 기존 SigLIP보다 더 나은 성능을 보였습니다. 특히 지리적 위치 파악(geolocalization) 작업에서 개선 폭이 크게 나타났습니다.
- Variable aspect and resolution (NaFlex)
기존 표준 모델들은 이미지를 모두 정사각형 형태로 바꾼 뒤 처리하는 방식이라, 원래의 비율이 망가지는 문제가 있었습니다.
반면, 함께 공개된 'NaFlex' 변형 모델은 각 이미지가 가진 고유한 가로-세로 비율을 그대로 유지합니다. 따라서 영수증이나 웹페이지 스크린샷, 문서처럼 비율이 흐트러지면 결과에 큰 영향이 가는 OCR이나 문서 이해 작업에서 압도적인 이점을 제공합니다.
SigLIP 2가 열어갈 미래
SigLIP 2는 비전-언어 모델 개발에서 ‘개별 성능 최적화’보다는 ‘총체적 능력 강화’에 초점을 맞춘 새로운 전환점입니다. 기존 모델에 비해 압도적인 성능과 세부 부분 인식, 다국어 지원은 물론 사회적 책임까지 고려한 공정성 까지. SigLIP 2는 여러 방면에서 한층 더 진화한 모습을 보여주었습니다.
Google DeepMind는 ViT-B(86M)부터 g(1B)까지 다양한 크기의 모델을 오픈소스로 공개했습니다. 전 세계 개발자와 연구자들이 이 강력한 기술을 바탕으로 새로운 혁신을 만들어갈 수 있게 된 셈인데요. 한번 SigLIP 2가 이끌 차세대 AI 애플리케이션의 물결을 기대해 봅니다! |